A Verified Coverage Checker
This post is Day 18 of Proof Assistants Advent Calendar 2025.
Since around last spring, I have been mechanizing a pattern-matching coverage-checking algorithm. In this post, I will introduce the algorithm and my mechanization in Agda.1
Table of contents
Background
Coverage checking for pattern matching is a static analysis that checks whether a match satisfies two nice properties: exhaustiveness and non-redundancy.
- Exhaustiveness: every value matches some pattern.
- Non-redundancy: there is no clause that execution can never reach.
Let’s look at an example. In the following OCaml program, we implement a simple access-control function allowed using pattern matching.
type role = Staff | Manager | Admin
type action = View | Edit | Approve | Delete
let allowed role action =
match role, action with
| _, View -> true
| (Manager | Staff), Delete -> false
| manager, Approve -> true
| Staff, Approve -> falseIs this pattern exhaustive? No. For example, there is no clause for the case Staff, Edit.
Evaluating allowed Staff Edit will raise a runtime exception.
What about non-redundancy? It also fails.
In the third clause, the first pattern is not the constructor pattern Manager but the variable pattern manager.
So Staff, Approve also matches the third clause, and the fourth clause is never reached.
When there is a redundant clause, it may indicate a mismatch between the programmer’s intended case split and the code actually does.
As this example shows, coverage checking is an important analysis for improving program safety and predictability.
Many algorithms for coverage checking have been proposed.
- 2
- the foundation of Rust’s coverage-checking algorithm
- was once implemented in the OCaml compiler
- handles only a simple pattern language, but is still practical (most real programs use mostly simple patterns)
- Lower your guards3
- the foundation of Haskell’s coverage-checking algorithm
- supports more complex patterns (GADTs, view patterns, pattern synonyms, strictness, …)
- …
These algorithms often come with pen-and-paper correctness proofs, which is great!
But what about the implementation? Even with a correct proof on paper, a buggy implementation can still produce wrong warnings or miss real bugs. Since coverage checking is important, it is natural to want a verified coverage checker. After some digging (including verified compilers such as CakeML), I was not able to find many such implementations.4 So I decided to formalize a coverage-checking algorithm and obtain a verified implementation in my favorite proof assistant, Agda.
I chose as the target algorithm. Because is relatively simple, I expected it to be feasible to mechanize in a proof assistant. It also seems like a good foundation for future work on mechanizing more complex and/or more efficient algorithms.
An overview of
The setting of
As mentioned above, works over a fairly simple setting. Concretely, we consider only algebraic data type values, and only three forms of patterns: wildcard patterns, constructor patterns, and or-patterns. For coverage checking, we can treat variable patterns as wildcards. We use for constructors, for values, and for patterns.
We write value vectors and pattern vectors as and , and a pattern matrix (a list of pattern vectors) as .
Each row of the pattern matrix corresponds to a clause of a match expression.
We also introduce the binary relation (“matches”).5 The match relation between a (single) value and a pattern is defined in the standard way:
A value vector matches a pattern vector when all corresponding components match. In particular, the empty value vector matches the empty pattern vector.
Finally, we define the match relation between a value vector and a pattern matrix.
Values and patterns are typed implicitly, and is only defined when the value and the pattern have the same type.
Let’s see an example. Consider the following list type:
type mylist = Nil | One of unit | Cons of unit * mylistNow consider the following pattern matrices and value vectors:
In this situation, we have and , because they match the first and second rows of , respectively. On the other hand, . Also, we can see that .
Pattern usefulness
is not directly an algorithm for exhaustiveness or non-redundancy. It checks a property called usefulness. Usefulness is defined as follows:
Definition (Usefulness)
A pattern vector is useful with respect to a pattern matrix (written ) if:
- there exists a value vector such that
- does not match any row of (), and
- matches ().
Continuing the earlier example, for , the wildcard pattern vector is useful. A witness is , since and . Also, we can check that the 6th row of is not useful with respect to the submatrix consisting of rows 1–5 of .
But, why do we care about usefulness? It is because both exhaustiveness and non-redundancy can be rephrased in terms of usefulness.
Lemmas
- is exhaustive the vector of wildcard patterns is not useful with respect to ( )
- the -th clause of is non-redundant the -th clause is useful with respect to the preceding clauses ( )
The two usefulness examples above exactly showed that is not exhaustive and that the 6th clause of is redundant.
Using these equivalences, we can implement exhaustiveness and redundancy checking algorithms on top of .
How works
Let’s look at in more detail. Its specification is:
- Input: a pattern matrix and a pattern vector
- Output: a boolean
- Specification:
- the types of the corresponding columns of and must agree
- it returns true iff is useful with respect to ( )
Operationally, searches for a witness value vector for usefulness. It case-splits on the structure of and narrows down what the structure of the witness could be. At the same time, it shrinks the problem by discarding rows of that the witness does not definitively match. Then it recursively solves the smaller subproblem.
When is empty
This is the base case of the recursion, and it solves the simplest usefulness problem. Here, is a 0-column pattern matrix (a matrix whose rows are empty pattern vectors). Recalling that the empty value vector matches the empty pattern vector, we just need to return whether has no rows (i.e. whether it is the empty matrix). If has no rows, the empty value vector is a witness for usefulness. If has at least one row, then and is not useful.
When the head of is an or-pattern
We recursively solve the cases where we choose the left or the right side, and take the disjunction.
When the head of is a constructor pattern
If the head of is , then any witness value vector must also start with a value of the form . Therefore, we can discard rows of whose head pattern is with . Let be this filtering operation (called specialization). Then is defined as follows. Nested patterns inside the constructor pattern are pulled out and prepended to the pattern vector:
The definition of is the following. It expands or-patterns into two rows and expands wildcard patterns into as many wildcards as the arity of the constructor.
When the head of is a wildcard
Unlike the constructor case, the wildcard pattern does not determine the shape of the first value of the witness value vector. So in principle we need a brute-force approach, specializing by every possible constructor and taking the disjunction.
However, we can sometimes avoid brute force using information from . Consider the following and :
Looking at the first column of , among the constructors of mylist, we see Nil and One, but not Cons.
Now suppose the witness value vector starts with the value of the form Cons(...).
Then it can only match rows whose first pattern is a wildcard (rows 3 and 4), so we can focus only on those rows:
Now the first column of both and is entirely wildcards. Since that column carries no information, usefulness is determined only by the second column, so we obtain the following smaller problem:
In this way, if there exists a missing constructor in the first column of , we can pick a witness starting with and shrink the problem efficiently without brute force.6
Putting this together, when the head of is a wildcard, is defined as:
Here, is the set of constructors that appear in the first column of . extracts only the suffixes (columns 2..n) of rows whose head is a wildcard, and is defined as follows. As with , if the head is an or-pattern, we expand it into two rows:
That’s the basic idea behind how works.
Highlights of the mechanization
Now let’s finally look at the mechanization. That said, most of what I did is simply translating the operational idea above into Agda, so here I will only highlight a few key parts.
Correctness proof
This is the main part of the mechanization. In this project, I proved correctness by implementing an evidence-producing version of . The original returns only a boolean, but my implementation explicitly computes and returns evidence for usefulness.
Here is the pseudocode.
The type Useful is a record type that encodes the definition of usefulness in Agda.
It contains a witness, and proofs that it really is a witness.
The function decUseful implements .
Its return type is Dec (Useful P ps), so if ps is useful with respect to P it returns the evidence. Otherwise, it returns a proof that no evidence exists.
record Useful (P : PatternMatrix) (ps : Patterns) : Type where
field
witness : Values
witness-does-not-match-P : witness ⋠ P
witness-matches-ps : witness ≼ ps
data Dec (A : Type) : Type where
Yes : A → Dec A
No : ¬ A → Dec A
decUseful : (P : PatternMatrix) (ps : Pattern) → Dec (Useful P ps)With this approach, implementation and correctness proof come together, and we get a correct-by-construction implementation.
Moreover, the witness returned by decUseful is useful for improving error messages. It can be used to display a concrete example of what is not covered.
Extending usefulness
I just said the witness can be used for error messages. But if we think about real compilers, they typically display an uncovered pattern, not an uncovered value.
For example, consider the following OCaml program:
let foo (xs : mylist) (ys : mylist) : string =
match xs, ys with
| Nil, _ -> "nil-wildcard"
| _ , Nil -> "wildcard-nil"The OCaml compiler reports:
Warning 8: this pattern-matching is not exhaustive.
Here is an example of a case that is not matched:
((One _|Cons (_, _)), (One _|Cons (_, _)))It is great that it shows patterns rather than values, because it is more informative.
So I would like decUseful to return a witness pattern vector (or a non-empty set of them), and for that we need to extend both the definition of usefulness and the algorithm.
How should we extend the definition? Recall the original definition of usefulness. In the picture below, we can think of and as describing sets of value vectors, and a witness as a point in the set difference .
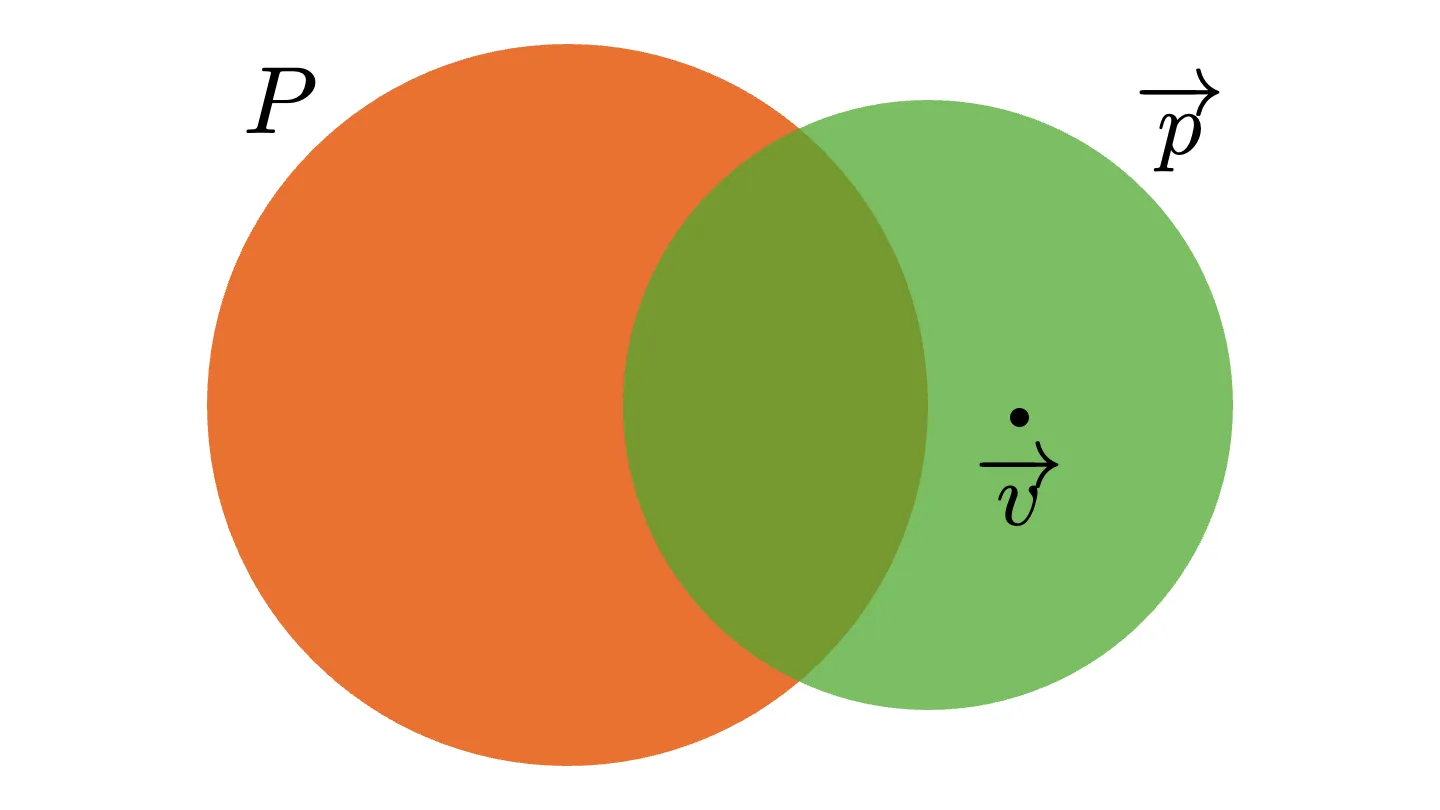
In the extended definition, we want witnesses to be pattern vectors. So we should “inflate” a witness from a point to a set, like in the picture. In other words, we extend a witness to be a subset of the set difference.

Formalizing this intuition:
Definition (Extended Usefulness)
A pattern vector is useful (in the extended sense) with respect to a pattern matrix if:
- there exists a pattern vector such that
- is disjoint from ()
- is subsumed by ()
“Is disjoint from” instead of “does not match”, and “is subsumed by” instead of “matches”.
What should the algorithm look like for the extended definition? It does not need big changes. Roughly speaking, the only places we need to change are where the original algorithm took disjunctions (or-patterns, and brute-force splitting for wildcards) in case you want compute all the witnesses. Instead of taking a disjunction, we take a union and return all witnesses.
The pseudocode looks like this.
Besides the extended Useful, the return type of decUseful is now Dec (NonEmpty (Useful P ps)), so it returns a non-empty list of witnesses.
record Useful (P : PatternMatrix) (ps : Patterns) : Type where
field
witness : Patterns
witness-disjoint-from-P : ∀ {vs} → vs ≼ witness → vs ≼ P → ⊥
ps-subsumes-witness : ∀ {vs} → vs ≼ witness → vs ≼ ps
decUseful : (P : PatternMatrix) (ps : Pattern) → Dec (NonEmpty (Useful P ps))I have not proved completeness of the witnesses returned by decUseful yet (i.e. that they fully cover ), so that is still future work.
Termination proof
Termination matters too because we do not want the compiler to loop forever in coverage checking. However, the original paper does not contain a termination proof for .
Proving termination for is tricky, because (as we saw above) it has a complex recursion structure. It is not structural recursion, so we will need well-founded recursion However, finding a good measure is the hard part. The following aspects are particularly problematic:
- and expand or-patterns.
- can expand a wildcard into multiple wildcards.
Because of these, a naive pattern size measure does not necessarily decrease, and it can even increase. Luckily, I managed to find a suitable measure using roughly the following idea:
- count pattern size after fully expanding or-patterns7
- do not count wildcards
- since (2) can break strict decrease in some cases, combine another decreasing measure (such as the number of columns of the pattern matrix) in a lexicographic order
Compiling to Haskell with agda2hs
Since the goal is a verified implementation of a coverage checker, I want to make the Agda code runnable. For that, I used agda2hs. agda2hs translates a subset of Agda into Haskell while aiming to stay close to the original code (and to generate human-readable Haskell), unlike Agda’s built-in Haskell backend.
With agda2hs, we specify which parts of the Agda code should be erased in Haskell using the erasure feature.
Parts annotated with @0 (or @erased) in Agda code are erased in the generated Haskell code.
For example, suppose we annotate the Useful type as follows.
witness-disjoint-from-P and ps-subsumes-witness are proof-only information, so we want to erase them.
record Useful (@0 P : PatternMatrix) (@0 ps : Patterns) : Type where
field
witness : Patterns
@0 witness-disjoint-from-P : ∀ {vs} → vs ≼ witness → vs ≼ P → ⊥
@0 ps-subsumes-witness : ∀ {vs} → vs ≼ witness → vs ≼ psAfter running agda2hs, we get Haskell code like this, which is what we want.
newtype Useful = Useful { witness :: Patterns }By going through the whole mechanization and carefully adding @0 where appropriate, we can obtain code that is not so different from a direct Haskell implementation!
Conclusion
In this post, I talked about implementing a verified coverage checker in Agda.
Going forward, I would like to build on this mechanization and formalize more complex and/or more efficient algorithms. As a first step, I would like to formalize an optimized variant used in Rust that checks exhaustiveness and per-clause redundancy in one go.8
I have published the full mechanization on GitHub. The haskell branch also contains the Haskell code generated by agda2hs. I also host an HTML-rendered version of the code on GitHub Pages, so check it out if you are interested!
Footnotes
-
I planned to write this for last year’s Advent Calendar, but I got stuck on the termination proof, so it ended up being this year. I also wrote a paper about this mechanization, which is going to be published later. The preprint is available here. ↩
-
Luc Maranget, Warnings for Pattern Matching. This paper proposes several algorithms and is the most basic one among them. ↩
-
Sebastian Graf, Simon Peyton Jones, and Ryan G. Scott, Lower your guards ↩
-
As far as I could find, besides the concurrent work Joshua M. Cohen, A Mechanized First-Order Theory of Algebraic Data Types with Pattern Matching, I was not able to find much. That paper similarly claims that there was little prior work. ↩
-
I reverse the operand order compared to the original paper. This order feels more readable to me because it resembles set membership . ↩
-
If the types of constructor arguments include an empty type (Haskell’s
Void), then “some appropriate value vector” may not exist. So assumes that every type is inhabited. ↩ -
In practice, we also include the number of or-patterns in the size: if we only count size after expanding them, then the or-pattern step would no longer decrease the measure. ↩
-
Currently, we have to run exhaustiveness checking and (separately) redundancy checking for each clause, which means calling a number of times proportional to the number of clauses. ↩